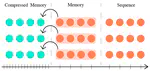
With the release of closed-source ChatGPT, GPT-4, and open-source LLaMa models, the LLM development has seen tremendous improvements in recent months. While we are hyped with the fact that these LLMs are capable of many tasks, we have also noticed again and again that these LLMs hallucinate content.