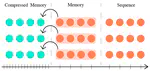
With the big noises made by ChatGPT, many different industries have noticed the value of LLM technologies. Unsurprisingly, the video game industry is one of them. In this blog, I introduce several cool demos/WIPs that I’ve recently found, and share my opinions on why they might have profound influences on the future of video game industry.