Jun 20, 20262 min readEngineeringReproducing Orcheo SIGIR Paper's Typesetting from Vision AloneAn experiment in asking Codex to recreate the XHTML typesetting of the Orcheo paper from purely visual understanding, without text extraction or OCR.aicodexxhtmlpublishingRead post
Apr 16, 20267 min readEngineeringOrcheo and Harness Engineering: Where It Fits and Where It Can Grow NextA grounded look at how the Orcheo ecosystem relates to harness engineering: where Orcheo already reduces agent failure modes through structure, observability, and guardrails, and where stronger verification and behavioural checks are next on the roadmap.orcheoharness-engineeringai-agentsworkflowsRead post
Jan 27, 20242 min readAIWhat Can Humans Learn FROM AI Models?Exploring what humans can learn from AI models like ChatGPT, examining both technical and philosophical implications of human-AI interaction.Philosophy of AICritical ThinkingExistential InquiryRead post
Nov 25, 20232 min readCareerFun Fact: One Good Job Offer Is All You NeedJob seekers should focus on securing a single quality offer rather than pursuing multiple positions simultaneously.Job HuntingCareer AdvicePersonal DevelopmentRead post
Nov 12, 20237 min readCareerNavigating The Job Hunting MazeSome advice on LLM job hunt in 2023, covering preparation, strategy, and understanding the nuances of the job market.Job HuntingLLM CareersCareer AdvicePersonal DevelopmentRead post
Sep 23, 20232 min readIdeasNotes for Creativity TrainingIdeas on how to redirect technology and gaming addiction toward productive outcomes, from AI-powered education to elderly companion bots.CreativityAIIdeasRead post
Sep 20, 20232 min readAI EthicsJob Invitations From Adult Industry Are Welcome, but Not in the Way You Are Thinking OfIt is all about responsibility — reflecting on AI ethics, the adult industry, and what it means to be a responsible technologist.Responsible AIPersonal OpinionsRead post
Sep 11, 20232 min readEducationBreak Time Banned in Chinese Schools. What Now?Discovering that schools in China have banned unsupervised break times, restricting students to classrooms — and why this matters.EducationCurrent AffairsPersonal OpinionsRead post
Aug 13, 20232 min readAIHas the AI-Era Come to Video Games Already?Exploring how large language models and AI technologies are transforming video game development and player experiences.Deep LearningNLPLLMVideo GamesRead post
Aug 9, 2023< 1 min readAIOne Source of LLM Hallucination Is Exposure BiasDiscussing how LLM hallucinations stem from exposure bias — both memorized knowledge and corpus-based heuristics from training data.Deep LearningNLPLLMHallucinationRead post
May 16, 2020< 1 min readPaper NotesTransformer Align ModelNotes on training transformers to perform both translation and alignment tasks simultaneously.Deep LearningNLPRead post
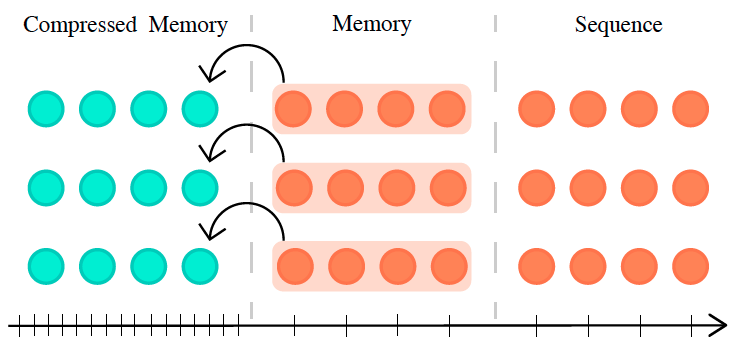
May 12, 20202 min readPaper NotesCompressive TransformersNotes on Compressive Transformers — a model that condenses old memories and stores them in compressed memory buffers for long-range sequence learning.Deep LearningNLPRead post
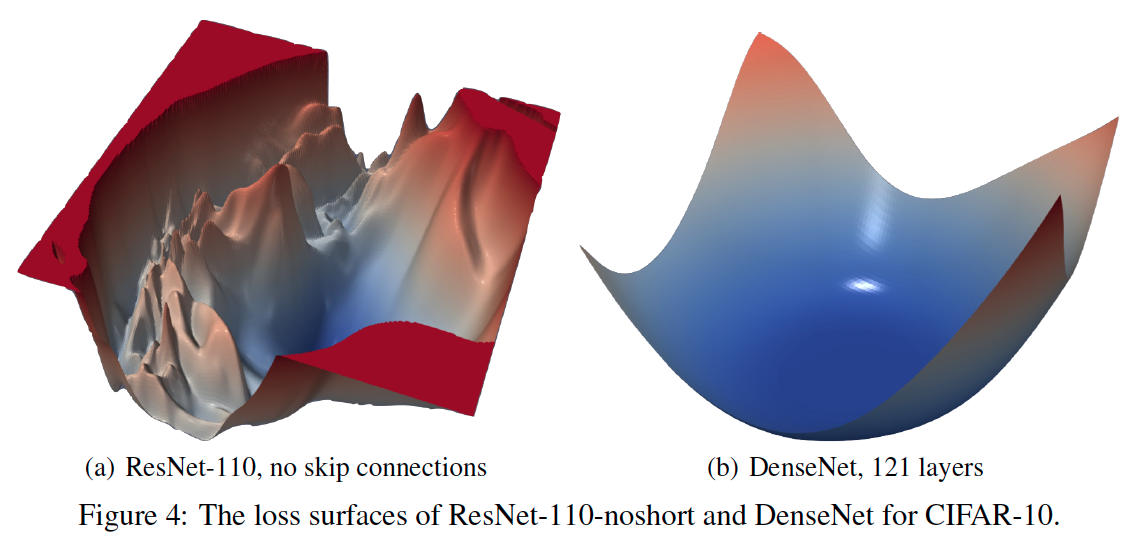
May 6, 2020< 1 min readPaper NotesVisualizing the Loss Landscape of Neural NetsNotes from the NeurIPS 2018 paper on why certain models train more easily and generalize better, through loss landscape visualization.Deep LearningRead post
Apr 28, 20202 min readPaper NotesAdaptive Computation TimeNotes on Adaptive Computation Time for Recurrent Neural Networks — comparing additive vs multiplicative halting probability approaches.Deep LearningRead post
Mar 2, 2020< 1 min readResourcesA Hub for Transformer Blogs and PapersA curated collection of resources about transformer models, including illustrated guides, GNN connections, and architectural improvements.Deep LearningRead post
Jun 20, 2019< 1 min readPaper NotesWhat's New in XLNet?Examining how XLNet improved upon BERT's architecture with Two-Stream Self-Attention and bidirectional data input.NLPDeep LearningBERTTransformerRead post