Compressive Transformers
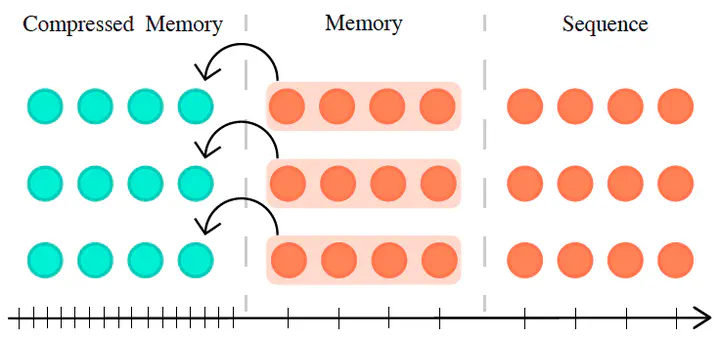
Built on top of Transformer-XL, Compressive Transformer1 condenses old memories (hidden states) and stores them in the compressed memory buffer, before completely discarding them. This model is suitable for long-range sequence learning but may cause too much computational burden for tasks that only have short sequences. Compressive Transformers can also be used as memory components in conjunction with other models.
Background
In the beginning, the authors draw the connection between their work and human brains by mentioning that humans memorize things via lossy compression.
We aggressively select, filter, or integrate input stimuli based on factors of surprise, perceived danger, or repetition – amongst other signals.
It’s often, if not always, good to see such insights of how AI works are inspired by humans. It’s also good to see that they relate their work to previous works, i.e. RNNs, transformers and sparse attention.
An RNN compresses previous memories into a fixed size hidden vector, which is space-efficient, but also results in its temporal nature and hence difficult to parallelize. Transformers, on the other hand, store all the past memories uncompressed, which can be beneficial for achieving better performances such as precision, BLEU, perplexity, etc, but it costs more and more computation and memory space with the sequence length growing. Sparse attention can be used to reduce computation, while the spatial cost remains the same.
Model design and training
The proposed Compressive Transformer uses the same attention mechanism over its set of memories and compressed memories, trained to query both its short-term granular memory and longer-term coarse memory.
If trained using original task-relevant loss only, it requires backpropagating-through-time (BPTT) over long unrolls for very old memories. A better solution is to use local auxiliary losses by stopping gradients and reconstructing either the original memory vectors (lossless objective) or attention vectors (lossy objective; reportedly to work better). The second choice for the auxiliary loss, in other words, means that we don’t care whether the original memory can be reconstructed or not, as long as the attention vector can be reconstructed, given the same query (brilliant!).
Some practical concerns
- The auxiliary loss is only used to train the compression module, as it harms the learning when the gradients flow back to the main network. This might also explain why I couldn’t reproduce ACT!
- Batch accumulation (4x bigger batch size) is used for better performance. It is observed in some works that bigger batch sizes lead to better generalization, but some other works found the opposite to be true (discussed in the papers and talks mentioned in my other post).
- Model optimization is very sensitive to gradient scales, so the gradient norms are clipped to 0.1 for stable results. This is typical for transformer variants.
- Convolution works best for memory compression.
Further thoughs/questions:
- Compressive Transformer improves the modeling of rare words. But why?
- In the discussion section, the authors pointed out that future directions could include the investigation of adaptive compression rates by layer, the use of long-range shallow memory layers together with deep short-range memory, and even the use of RNNs as compressors.
Shaojie Jiang
Manager AI
My research interests include information retrieval, chatbots and conversational question answering.